科普 | 云计算与大数据 服务与处理的孪生兄弟

在当今数字时代,“云计算”与“大数据”是两个被频繁提及的热词。它们常常携手出现,却又有着本质区别。简单来说,云计算是一种服务模式,而大数据则是一种处理对象和解决方案。理解二者的关系,能帮助我们更好地把握技术浪潮。
一、核心定义:服务与对象
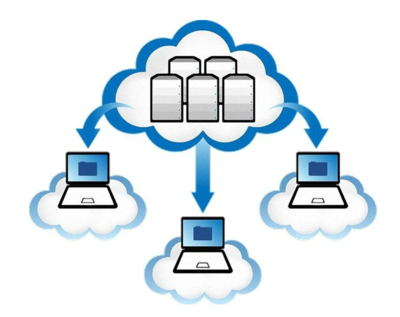
云计算的核心是“服务”。它通过互联网(即“云”)提供可伸缩的、按需使用的计算资源(如服务器、存储、数据库、网络、软件、分析等)。用户无需自建和维护复杂的IT基础设施,像用水用电一样,按使用量付费即可。其服务模式主要分为三类:
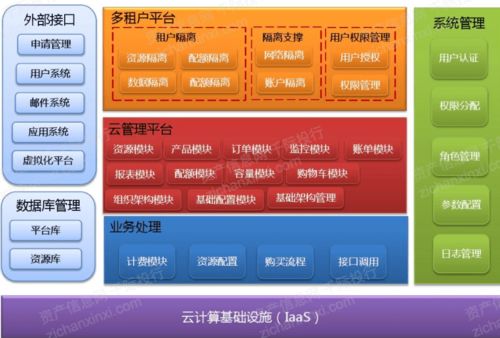
- IaaS(基础设施即服务):提供最基础的虚拟机、存储和网络资源,如亚马逊AWS的EC2。
- PaaS(平台即服务):提供开发和部署应用程序的平台与环境,如Google App Engine。
- SaaS(软件即服务):提供可直接使用的软件应用,如Office 365、Salesforce。
大数据的核心是“数据”及其“处理”。它指的是规模巨大(Volume)、类型多样(Variety)、产生速度快(Velocity)且价值密度低(Value)的数据集合。处理这些数据,需要新的技术架构(如分布式处理)来挖掘其洞察力(Veracity,即真实性或精确性,合称5V特征)。大数据关注的是如何采集、存储、管理、分析和应用这些海量数据。
二、核心区别:目标与角色
- 目标不同:云计算的目标是提供灵活、高效、低成本的计算资源与服务,优化IT架构和运营模式。大数据的目标是从海量数据中提取有价值的信息和洞见,以支持决策和发现新规律。
- 角色不同:云计算扮演着“赋能者”或“舞台”的角色。它为大数据处理提供了理想的运行环境——弹性的计算能力、海量的存储空间和强大的网络。没有云计算,处理大数据的成本和门槛将极高。大数据则是云计算上最典型、最重量级的“演员”之一。云计算的各种服务(如弹性计算、对象存储、数据仓库)被大数据技术栈(如Hadoop, Spark)广泛调用。
三、相辅相成:云计算如何服务大数据
云计算的服务模式完美契合了大数据的处理需求:
- 弹性伸缩:大数据处理任务(如周期性报表生成、实时流处理)往往计算量波动大。云计算的弹性伸缩能力可以按需分配资源,用时扩展,完事释放,极大降低成本。
- 海量存储:云存储服务(如AWS S3, Azure Blob Storage)提供了几乎无限、高持久性且成本低廉的数据存储池,是大数据的天然“数据湖”。
- 丰富服务:云厂商提供了大量托管的大数据服务,如亚马逊EMR(托管Hadoop/Spark)、谷歌BigQuery(云数据仓库)、Azure Synapse Analytics等。用户无需管理底层集群,即可直接进行大数据分析。
- 按需付费:大数据项目前期无需巨额硬件投资,可按分析任务实际使用的计算和存储资源付费,降低了创新试错的门槛。
四、比喻
用一个形象的比喻:
- 云计算就像一座现代化的“发电厂”和“电网”。它集中生产并随时随地提供电力(计算资源),用户只需插上插座(连接互联网)并按用电量付费。
- 大数据就像需要消耗巨量电力的“高科技工厂”(如芯片制造、AI训练)。这座工厂要运转,离不开强大、稳定且经济的电力供应。这座工厂产出的“智能产品”(数据洞见)又推动了社会进步。
结论:云计算与大数据并非竞争关系,而是紧密结合、相互驱动的共生体。云计算作为基础设施和服务模式,为大数据提供了经济高效的生存土壤;而大数据作为关键应用,则充分释放了云计算的价值和潜力。在数字化转型的道路上,二者共同构成了智能时代的基石。
如若转载,请注明出处:http://www.kmjcs.com/product/58.html
更新时间:2026-06-18 08:55:19